The problem of data sparsity has long plagued recommendation systems, and previous studies attempted to mitigate this issue by incorporating side information. However, this approach inevitably introduces side effects such as noise, availability issues, and quality issues. These problems hinder the effective modeling of user preferences and impact recommendation performance. In light of the advancements in large language models (LLMs) that possess a wide knowledge base and notable reasoning capabilities, we propose a novel framework called LLMRec that strengthens recommenders by applying three simple yet effective LLM-based graph augmentation strategies to recommendation system. Specifically, our approach is to make the most of the modality content within online platforms (e.g., Netflix, MovieLens) to augment heterogeneous interaction graph by i) reinforcing user-item interactive edges, ii) enhancing item node attributes, and iii) conducting user node profiling, intuitively from the natural language perspective. By doing so, we alleviate the challenges posed by sparse implicit feedback and low-quality side information in recommenders. Besides, to ensure the quality of the augmentation, we develop a denoised data robustification mechanism, including noisy implicit feedback pruning and MAE-based feature enhancement that help refine the augmented data and improve its reliability. In addition, we provide theoretical analysis to support the effectiveness of LLMRec and clarify the benefits of our method to facilitate model optimization. Experimental results demonstrate the effectiveness of our LLM-enhanced data augmentors, showcasing their superiority when compared to state-of-the-art recommendation techniques on benchmark datasets. To ensure reproducibility, we have made our code and augmented data publicly available at: https://github.com/HKUDS/LLMRec.git .

Figure 1: The LLMRec framework: (1) Three types of data augmentation strategies: i) augmenting user-item interactions; ii) enhancing item attributes, and iii) user profiling. (2) Augmented training with and denoised data robustification mechanism.
...

Figure 3: Constructed prompt for LLMs' completion including i) task description, ii) historical interactions, iii) candidates, and iv) output format description.
...
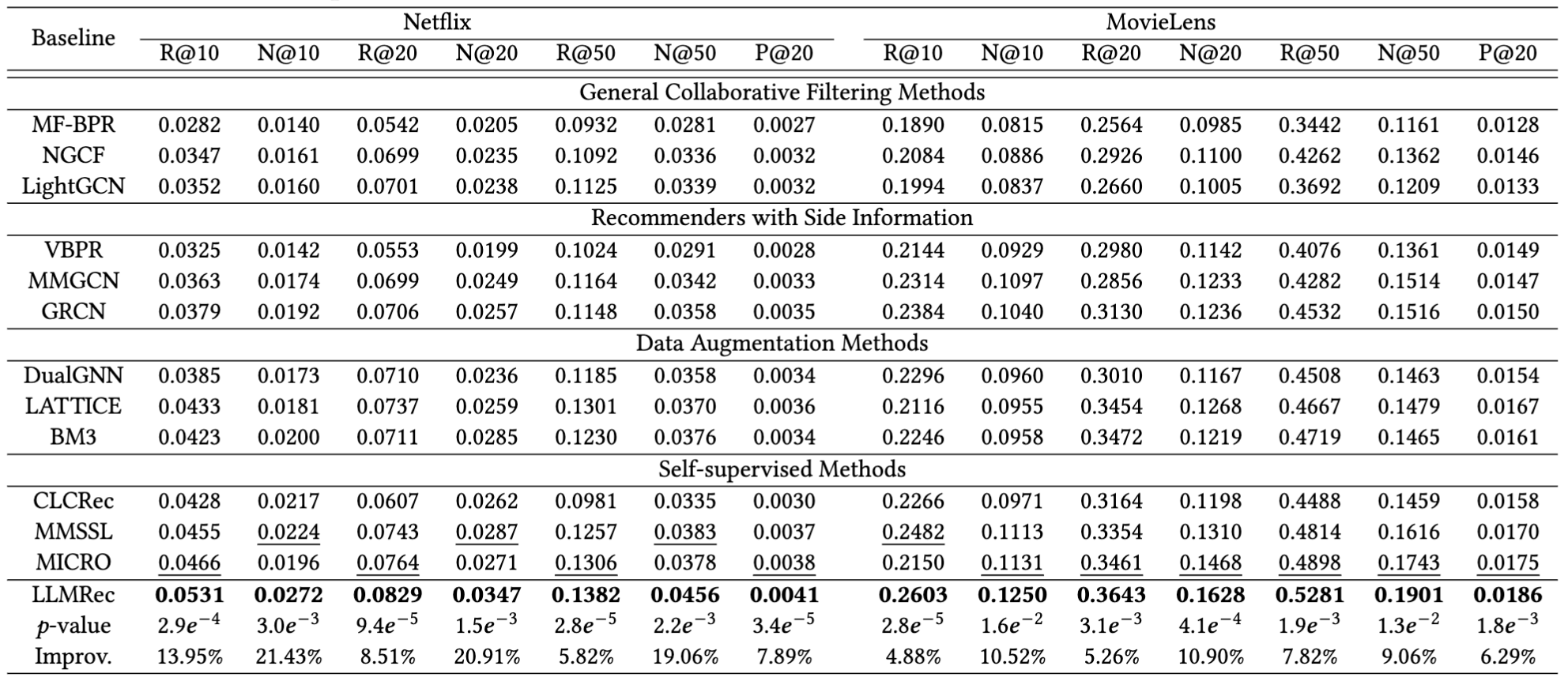
Figure 4: Performance comparison on different datasets in terms of Recall@10/20/50, and NDCG@10/20/50, and Precision@20.
...
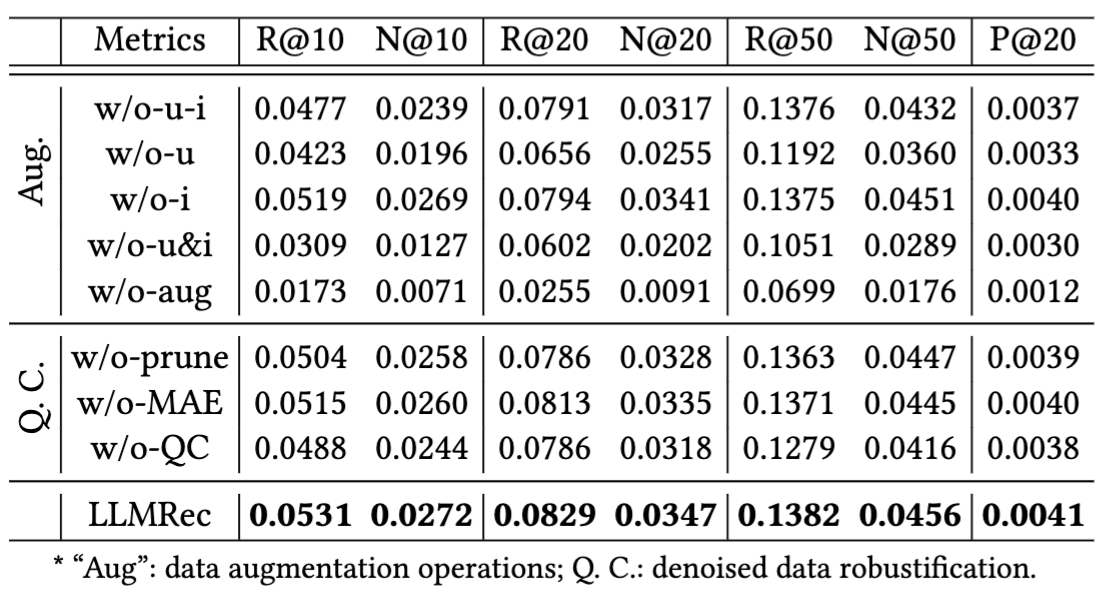
Figure 5: Ablation study on key components (\ie, data augmentation strategies, denoised data robustification mechanisms).
...
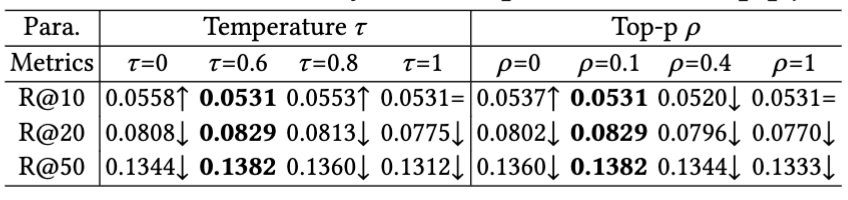
Figure 6: Parameter analysis of temperature and top-p.
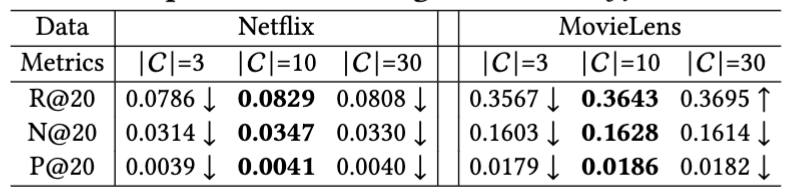
Figure 6: Analysis of key parameter (i.e., # candidate ) for LLM w.r.t. implicit feedback augmentation.
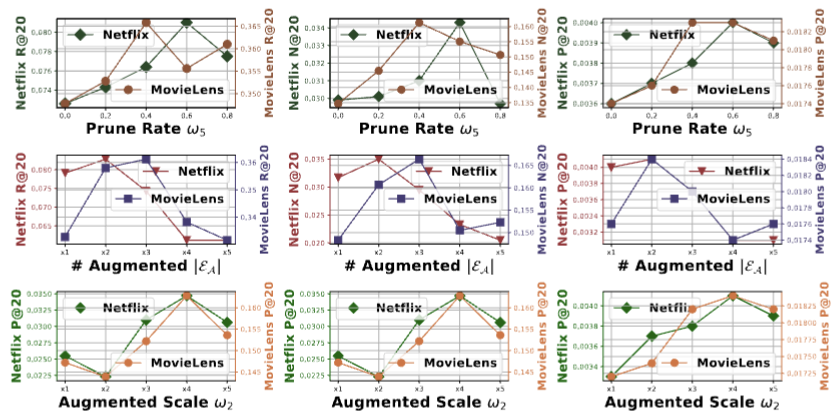
Figure 6: Impact of hyperparameters (i.e., prune rate, # augmented BPR training data, and augmented feature incorporate scale).
We conducted model-agnostic experiments on Netflix to validate the applicability of our data augmentation. Specifically, we incorporated the augmented implicit feedback and features, into baselines MICRO, MMSSL, BM3, and LATTICE. As shown in Fig.7, our LLM-based data improved the performance of all models, demonstrating their effectiveness and reusability. Some results didn't surpass our model, maybe due to: i) the lack of a quality constraint mechanism to regulate the stability and quality of the augmented data, and ii) the absence of modeling collaborative signals in the same vector space, as mentioned in Sec.~\ref{sec:side-incorporation}. The limited enhancement in the BM3 results could be attributed to its initial omission of the BPR loss, wherein solely the augmented data was employed for BPR computations.
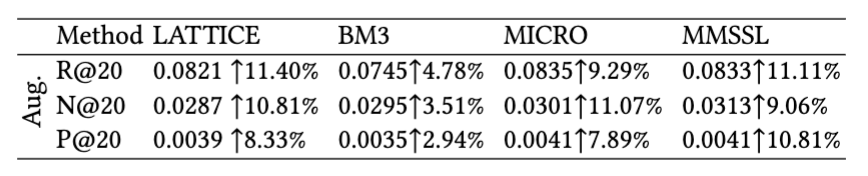
Figure 7: Model-agnostic experiment to evaluate the effectiveness of LLM-based data augmentation on different recommender in terms of R@20, N@20, and P@20.
To evaluate the cost-effectiveness of our data augmentation strategies, we compute the CIR as presented in Tab.X. The CIR is compared with the ablation of three data augmentation strategies and the best baseline from Tab.X and Tab.X. The cost of the implicit feedback augmentor refers to the price of GPT-3.5 turbo 4K. The cost of the our developed side information augmentation includes completion (using GPT-3.5 turbo 4K or 16K) and embedding (using text-embedding-ada-002). We utilize the HuggingFace API tool for tokenizer and counting. The results in Tab.X show that 'U' (LLM-based user profiling) is the most cost-effective .
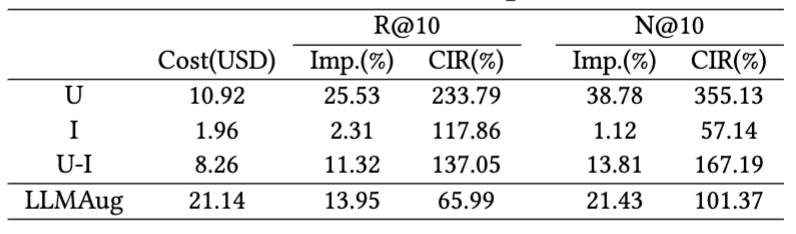
Figure 8: Inference efficiency study of our GraphGPT Training Efficiency with Graph Instruction Tuning.
@articles{wei2023llmrec,
title={LLMRec: Large Language Models with Graph Augmentation for Recommendation},
author={Wei, Wei and Ren, Xubin and Tang, Jiabin and Wang, Qinyong and Su, Lixin and Cheng, Suqi, and wang, junfeng and Yin, Dawei and Huang, Chao},
journal = {arXiv preprint},
year={2023}
}